An explaination of retrieval augmented generation (part II)
- 7 min read
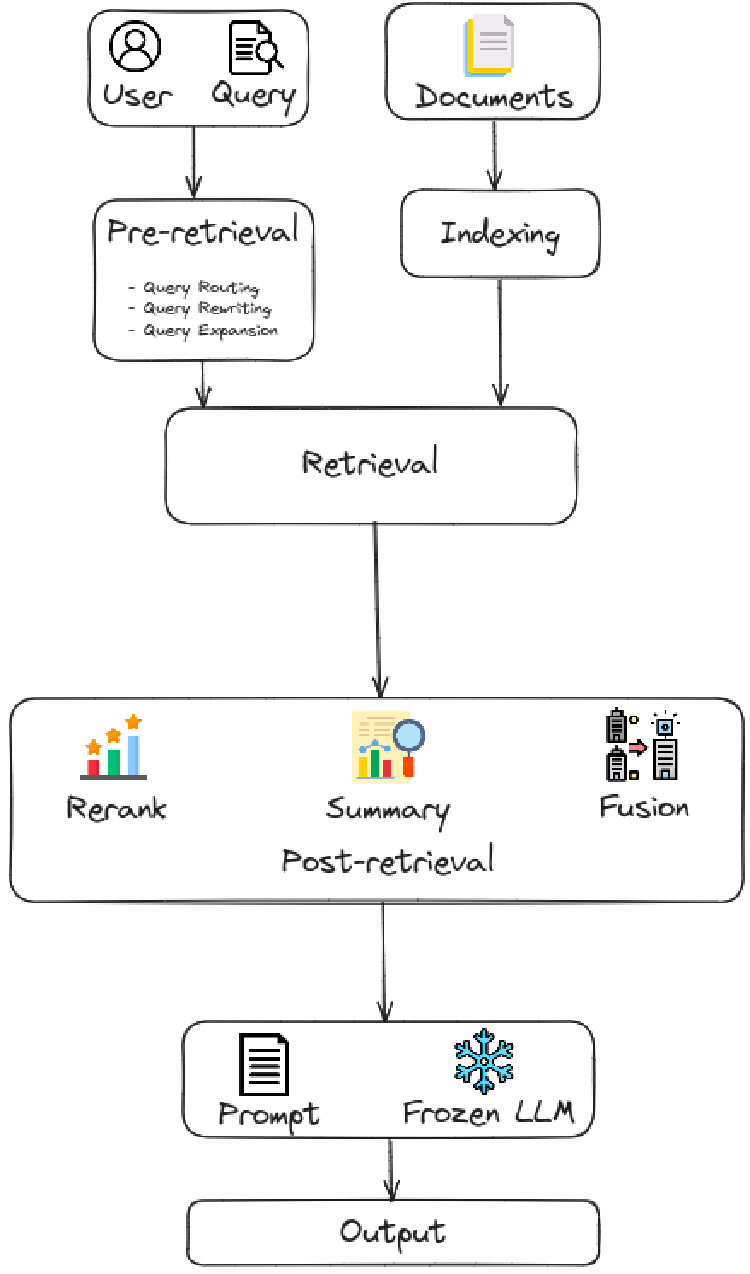
Coming up next the last part of the RAG series, in this part II, we focus on Advanced RAG, which introduces specific improvements to overcome the limitations of Naive RAG. Focusing on enhancing retrieval quality, it employs pre-retrieval and post-retrieval strategies. To tackle the indexing issues, Advacned RAG refines its indexing techniques through the use of a sliding window approach, fine-grained segmentation, and the incorporation of metadata. Additionally, it incorporates several optimization methods to streamline the retrieval process. Theoretically, there are two main groups of approaches in Advanced RAG:
Pre-Retrieval: In this stage, the primary focus is on optimizing the indexing structure and the original query. The goal of optimizing indexing is to enhance the quality of the content being indexed. This involves strategies: enhancing data granularity, optimizing index structures, adding metadata, alignment optimization, and mixed retrieval. While the goal of query optimization is to make the user’s original question clearer and more suitable for the retrieval task. Common methods include query rewriting query transformation, query expansion and other techniques.
Post-Retrieval: Once relevant context is retrieved, it’s crucial to integrate it effectively with the query. The main methods in post-retrieval process include rerank chunks and context compressing. Re-ranking the retrieved information to relocate the most relevant content to the edges of the prompt is a key strategy. Additionally, feeding all relevant documents directly into LLMs can lead to information overload, diluting the focus on key details with irrelevant content. To address this, post-retrieval efforts concentrate on selecting the essential information, emphasizing critical sections, and shortening the context to be proposed.
In this second part of the RAG series, we will focus exclusively on exploring the insights of pre-retrieval methods, reserving the discussion of post-retrieval methods for the subsequent part.
 |
|---|
| Pre-retrieval and Post-retrieval in Advanced RAG. |
Retrieval Source
Data Structure
Unstructured data: such as text, is the most widely used retrieval source, which are mainly gathered from corpus.
Semi-structured data: typically refers to data that contains a combination of text and table information, such as PDF.
Structured data: such as knowledge graphs (KGs), which are typically verified and can provide more precise information.
LLMs-Generated Content: Addressing the limitations of external auxiliary information in RAG, some research has focused on exploiting LLMs’ internal knowledge.
Data Granularity
Coarse-grained retrieval units can offer more relevant information but may include redundant content that distracts models in downstream tasks. Fine-grained units reduce redundancy but increase retrieval complexity and may compromise semantic integrity. Selecting the right retrieval granularity during inference can effectively enhance the performance of dense retrievers and downstream tasks.
Indexing Optimization
Chunking Strategy
The most common method is to split the document into chunks on a fixed number of tokens (100, 256, 512, etc.). Larger chunks can capture more context, but they also generate more noise, requiring longer processing time and higher costs. While smaller chunks may not fully convey the necessary context, they do have less noise. As a result, it makes us very difficult to strike a balance between semantic completeness and context length. Therefore, methods like Small2Big have been proposed, where sentences (small) are used as the retrieval unit, and the preceding and following sentences are provided as (big) context to LLMs.
Metadata Attachments
Chunks can be enriched with metadata information such as page number, file name, author, category timestamp. Subsequently, retrieval can be filtered based on these metadata, limiting the scope of retrieval.
Structural Index
- Hierarchical index structure: Files are arranged in parent-child relationships, with chunks linked to them. Data summaries are stored at each node, aiding in the swift traversal of data and assisting the RAG system in determining which chunks to extract.
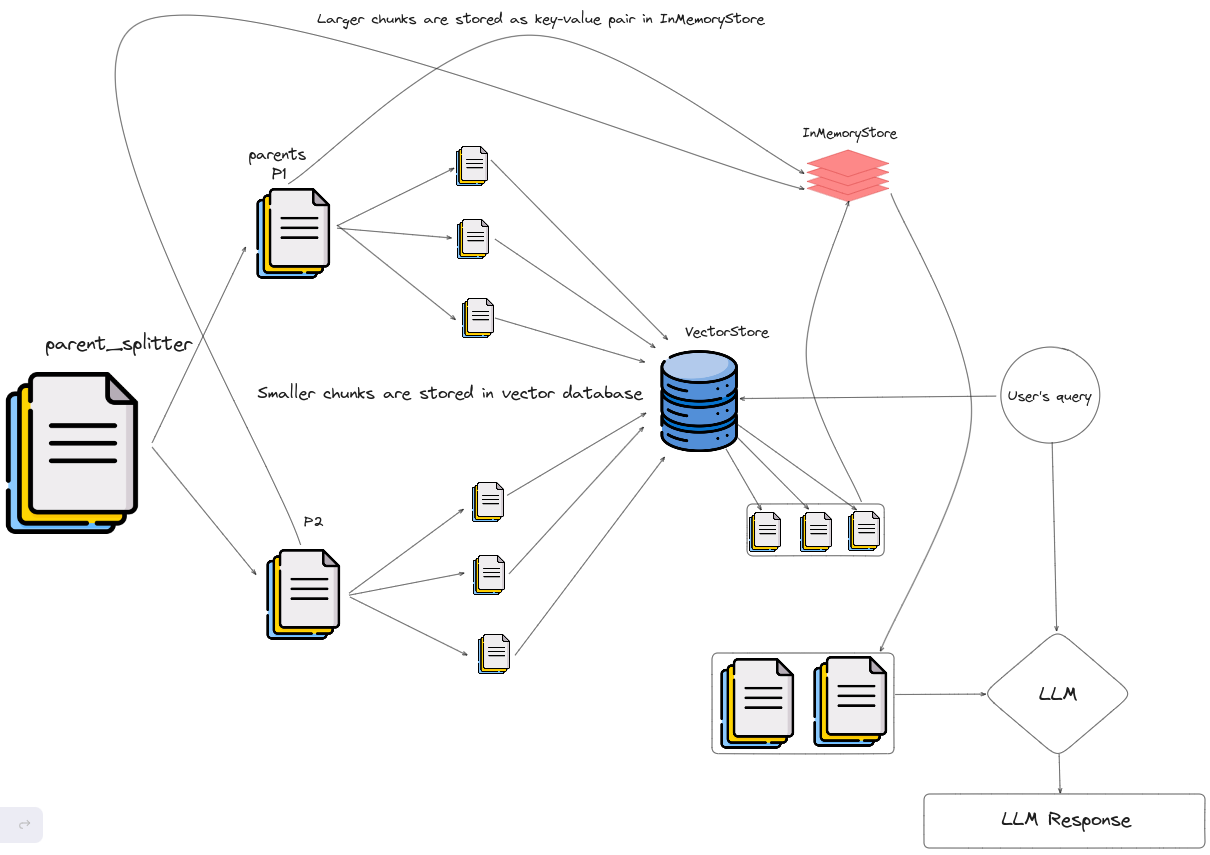 |
|---|
| An illustration of Parent Document Retriever. |
Knowledge Graph index: Utilize Knowledge Graph in constructing the hierarchical structure of documents contributes to maintaining consistency.
- Nodes: representing paragraphs or structures in the documents, such as pages and tables.
- Edges: indicating semantic/lexical similarity between paragraphs or relationships withing the document structure.
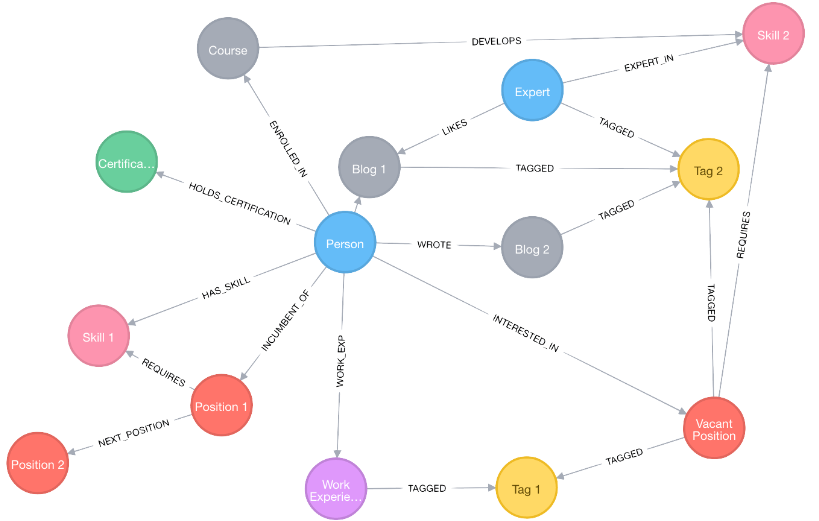 |
|---|
| An example of knowledge graph in Neo4j. |
Query Optimization
One of the primary challenges with Naive RAG is its direct reliance on the user’s original query as the basis for retrieval. Formulating a precise and clear question is difficult, and imprudent queries result in subpar retrieval effectiveness. There exists some problems related to user’s input query:
Sometimes, the question itself is complex, and the language is not well-organized.
Another difficulty lies in language complexity ambiguity.
Language models often struggle when dealing with specialized vocabulary or ambiguous abbreviations with multiple meanings, for example they may not discern whether “Apple” is name of a company or a fruit.
Query Expansion
Expanding a single query into multiple queries enriches the content of the query, providing further context to address any lack of specific nuances, thereby ensuring the optimal relevance of the generated answers.
Multi-Query: Automates the process of prompt tuning by using an LLM to generate multiple queries from different perspectives for a given user query.
Sub-Query: The process of sub-question planning represents the generation of the necessary sub-questions to contextualize and fully answer the original question when combined.
Chain-of-Verification(CoVe): The expanded queries undergo validation by LLM to achieve the effect of reducing hallucinations.
Query Transformation
The core concept is to retrieve chunks based on a transformed query instead of the user’s original query.
Query Rewrite
- Prompt LLM to rewrite the queries.
- To reduce the computational cost, utilized smaller language models, such as RRR (Rewrite-retrieve-read).
- Use prompt engineering to let LLM generate a query based on the original query for subsequent retrieval (HyDE - construct hypothetical documents (assumed answers to the original query)).
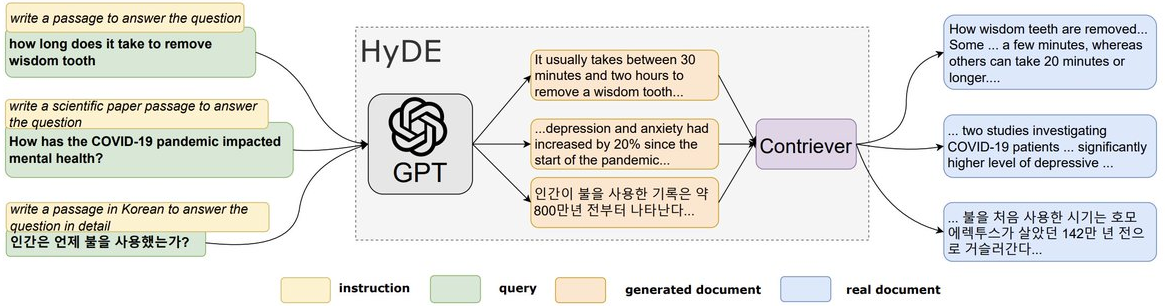 |
|---|
| An illustration of the HyDE model. |
Query Routing
Based on varying queries, routing to distinct RAG pipeline, which is suitable for a versatile RAG system designed to accomodate diverse scenarios.
Metadata Router/ Filter
- Extracting keywords (entity) from the query.
- Filtering based on the keywords and metadata within the chunks to narrow down the searh scope.
Semantic Router
- Is a method of routing involves leveraging the semantic information of the query
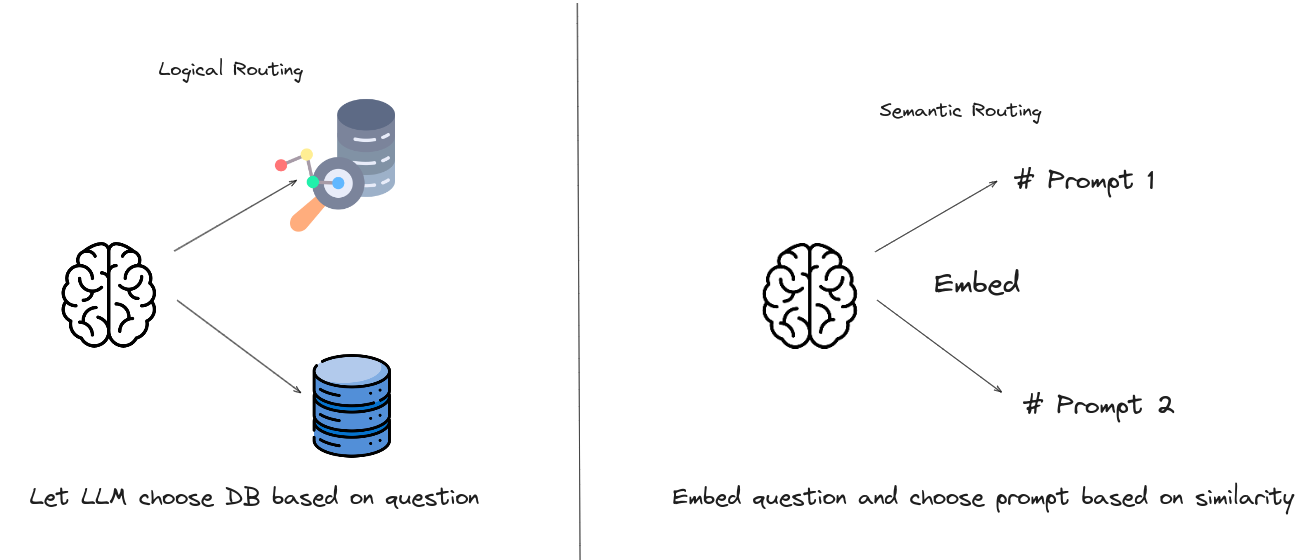 |
|---|
| An illustration of different types of query routing. |
Embedding
Mix/hybrid Retrieval
- Sparse and dense embedding approaches capture different relevance features and can benefit from each other by leveraging complementary relevance information. For instance, sparse retrieval models (BM25) can be used to provide initial search results for training dense retrieval models. Additionally, pre-training language models (PLMs) can be utilized to learn term weights to enhance sparse retrieval.
Fine-tuning Embedding Model
- In instances where the context significantly deviates from pre-training corpus, particularly within highly specialized disciplines such as healthcare, legal practice, and other sectors replete with proprietary jargon, fine-tuning the embedding model on your own domain dataset becomes essential to mitigate such discrepancies.
Adapter
Fine-tuning models may present challenges, such as integrating functionality through an API or addressing constraints arising from limited local computational resources. Consequently, some approaches opt to incorporate an external adapter to aid in alignment.
- UPRISE: Trained a lightweight prompt retriever to automatically retrieve suitable prompts from a pre-built pool for zero-shot tasks, optimizing multi-task capabilities of LLMs.
- AAR (Augmentation-Adapted Retriever): Introduced a universal adapter to handle multiple downstream tasks efficiently.
- PRCA: Added a pluggable, reward-driven contextual adapter to improve task-specific performance.
- BGM: Trained a bridge Seq2Seq model between a fixed retriever and LLM to transform retrieved information, allowing for dynamic selection and reranking of passages for queries.
- PKG: Developed a method for integrating knowledge into white-box models via directive fine-tuning, where the retriever module is substituted to generate relevant documents, enhancing model performance and addressing fine-tuning challenges.
Wrapping Up
Optimizing the indexing structure and original query are essential for enhancing the effectiveness and efficiency of information retrieval systems. Improving data granularity, optimizing index structures, and adding metadata boost content quality, while alignment optimization and mixed retrieval refine the process. Query optimization techniques like rewriting, transformation, and expansion ensure that user queries are clearer and more aligned with the retrieval task, resulting in more accurate and relevant outcomes. Together, these strategies build a more robust retrieval system, ultimately improving the user experience.
The next step in this process is to optimize the retrieved documents. Stay tuned for the upcoming part of this series, where we will explore this crucial aspect in greater detail!