Exploring the Different Variants of Transformer Models (Part I)
- 5 min read
Even though there’s been an explosion of different transformer models lately, they can still be grouped into three main categories: Encoders, Decoders, and Encoder-Decoders. Encoders are like the listeners in the group—they take in data and make sense of it, perfect for tasks like understanding text or classifying it. Decoders, on the other hand, are the storytellers, generating new sequences like writing text or translating languages. Then, we have the multitasker, the encoder-decoders, who do both listening and storytelling, which makes them great for jobs like translating or summarizing. In the very first episode of this series, let’s take a look at the transformer family trees and delve into Encoder-Only architectures
Encoders
Encoder-only models are a class of transformer-based architectures designed specifically for understanding and analyzing input data, such as text. These models focus solely on the encoding process, where they take input sequences and generate meaningful representations of the data. This is particularly useful for tasks like text classification, sentiment analysis, and named entity recognition, where the goal is to understand and process the input rather than generate new sequences.
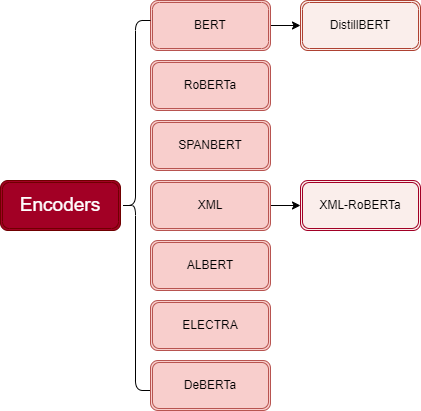 |
|---|
| An overview of Encoders family. |
The first encoder-only model based on the transformer architecture was BERT. Let go through the BERT model and some of its variants
BERT (Bidirectional Encoder Representations from Transformers)
BERT is pretrained using two key objectives: predicting masked tokens in text, known as masked language modeling (MLM), and determining whether two text passages are sequential, called next-sentence prediction (NSP). The model was pretrained on the BookCorpus and English Wikipedia, allowing it to be fine-tuned on various natural language understanding (NLU) tasks with minimal data.
DistilBERT
While BERT provides excellent results, its size can make it challenging and costly to deploy. DistilBERT addresses this issue by using knowledge distillation during pretraining. This process reduces the model’s size by 40%, increases its speed by 60%, and retains 97% of BERT’s performance.
RoBERTa (Robustly optimized BERT approach)
Following BERT’s success, researchers found that adjusting the pretraining scheme could enhance its performance. RoBERTa was trained longer, with larger batches and more data, and removed the NSP task, resulting in significant performance improvements over the original BERT model.
SPANBERT
SpanBERT is another variation of BERT, primarily used for Question Answering tasks. Designed to enhance the original BERT model, SpanBERT focuses on predicting text spans rather than individual tokens. Unlike BERT, which masks random tokens in the input, SpanBERT masks random continuous spans of text. This allows SpanBERT to outperform BERT by predicting the entire content of a masked span without relying on individual token representations. It uses boundary tokens at the start and end of the span to create a fixed-length representation.
XLM (Cross-lingual Language Model)
XLM explored several pretraining objectives for multilingual models, including autoregressive language modeling and MLM. Additionally, it introduced translation language modeling (TLM), extending MLM to multiple language inputs. XLM achieved state-of-the-art results on various multilingual NLU benchmarks and translation tasks.
XLM-RoBERTa (XLM-R)
Building on XLM and RoBERTa, XLM-R upscaled the training data using the Common Crawl corpus, creating a 2.5 terabyte dataset. It trained an encoder with MLM on this monolingual dataset, dropping the TLM objective. This approach significantly outperformed XLM and multilingual BERT variants, particularly in low-resource languages.
ALBERT (A Lite BERT)
ALBERT introduced three key changes to make the model more efficient: separating the token embedding dimension from the hidden dimension to reduce the size of embeddings, sharing parameters across layers to further decrease the number of parameters, and replacing the NSP objective with sentence-order prediction, which determines if the order of two sentences has been swapped. These changes allow the training of larger models with fewer parameters, resulting in better performance on NLU tasks.
ELECTRA
ELECTRA addresses a limitation of the MLM objective, where only masked token representations are updated during training. It uses a two-model approach: a small generator model predicts masked tokens, and a discriminator model identifies which tokens in the generated sequence were originally masked. This setup requires the discriminator to perform binary classification for every token, making training 30 times more efficient. The discriminator is fine-tuned for downstream tasks like a standard BERT model.
DeBERTa (Decoding-enhanced BERT with disentangled attention)
DeBERTa introduces two architectural innovations. First, it separates position information from the content vector, using two independent attention mechanisms to process both content and relative position embeddings at each layer. Second, it includes an absolute position embedding before the SoftMax layer in the token decoding head, highlighting the importance of a word’s absolute position, particularly for decoding. DeBERTa was the first model, in an ensemble setting, to surpass human performance on the SuperGLUE benchmark.
To sum it up, our brief exploration of encoder-only models highlights their critical role in efficiently processing and understanding data, especially in natural language processing tasks. These models form the backbone of many cutting-edge AI applications, offering robust performance with their specialized architecture.
Looking ahead, we’ll continue this journey by examining decoder-only and encoder-decoder models, comparing their strengths and use cases. Make sure to join us as we delve deeper into the intricacies of AI model design and application.
References:
Natural Language Processing with Transformers by Lewis Tunstall, Leandro von Werra, and Thomas Wolf