An explaination of retrieval augmented generation (part IV)
- 4 min read
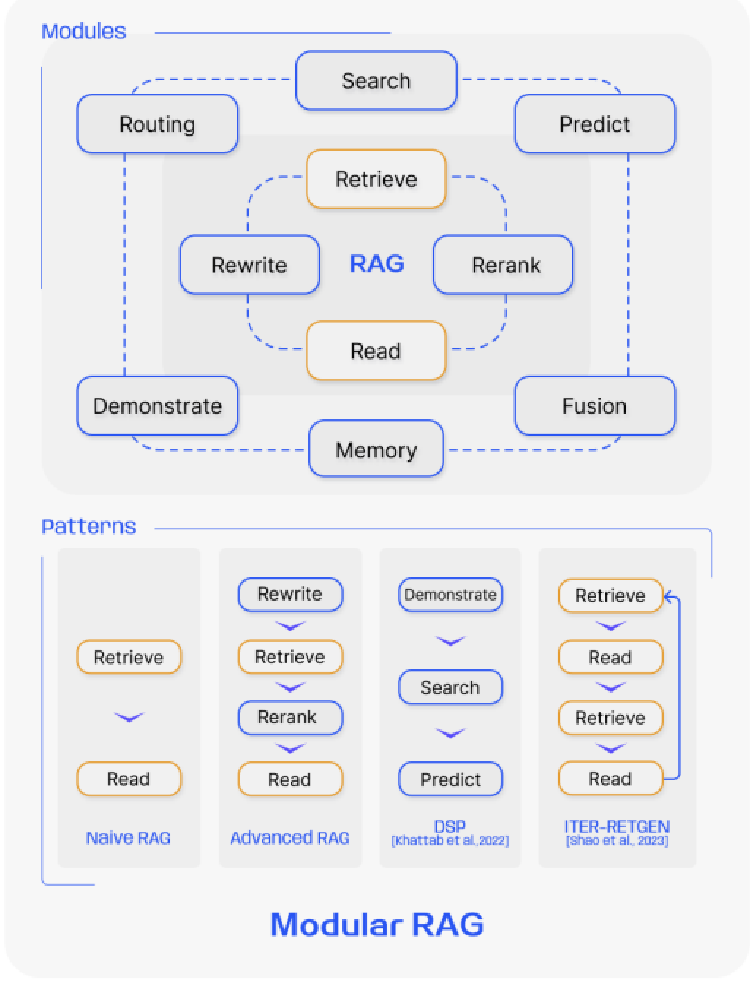
In the domain of RAG, the standard practice often involves a singular (once) retrieval step followed by generation, which can lead to efficiencies and sometimes is typically insufficient for complex problems demanding multi-step reasoning, as it provides a limited scope of information. To mitigate this, the modular RAG architecture advances beyond the former two RAG paradigms, offering enhanced adaptability and versatility. It incorporates diverse strategies for improving its components, such as adding a search module for similarity searches and refining the retriever through fine-tuning.
Let’s explore the factors driving the rising trend of Modular Retrieval-Augmented Generation (Modular RAG).
New Modules
The Modular RAG framework introduces specialized components to improve retrieval and processing capabilities.
The Search module is adaptable to different scenarios, allowing direct searches across multiple data sources, such as search engines, databases, and knowledge graphs, by using LLM-generated code and query languages. RAGFusion overcomes traditional search limitations by employing a multi-query approach that expands user queries into different perspectives. It uses parallel vector searches and smart re-ranking to reveal both obvious and hidden knowledge.
The Memory module uses the LLM’s memory to guide retrieval, creating a limitless memory pool that iteratively improves alignment between the text and data distribution.
Routing within the RAG system optimizes navigation through various data sources, selecting the best path for a query, whether it requires summarization, specific database searches, or integrating different information streams.
The Predict module reduces redundancy and noise by generating relevant context directly through the LLM, ensuring accuracy.
Finally, the Task Adapter module customizes RAG for different downstream tasks, automating prompt retrieval for zero-shot inputs, and creating task-specific retrievers with few-shot query generation.
This comprehensive framework not only simplifies the retrieval process but also greatly enhances the quality and relevance of the retrieved information, supporting a wide range of tasks and queries with increased precision and flexibility.
New Patterns
Modular RAG offers remarkable adaptability by allowing module substitution or reconfiguration to address specific challenges. This goes beyond the fixed structures of Naive and Advanced RAG, characterized by a simple “Retrieve” and “Read” mechanism. Moreover, Modular RAG expands this flexibility by integrating new modules or adjusting interaction flow among existing ones, enhancing its applicability across different tasks.
Iterative Retrieval
 |
|---|
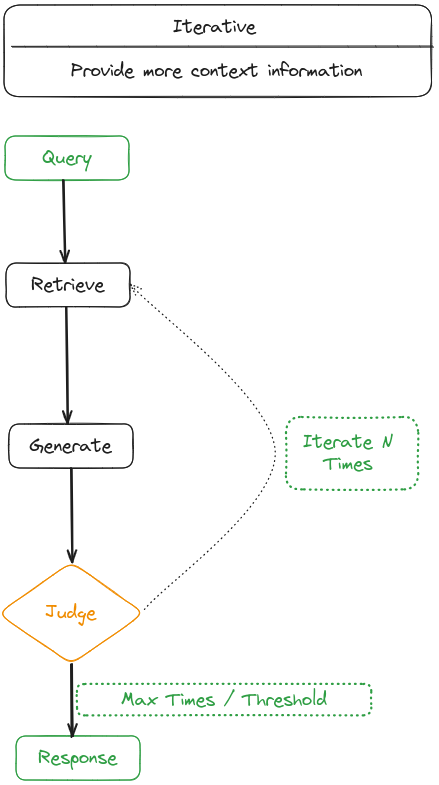
| Iterative retrieval involves alternating between retrieval and generation, allowing for richer and more targeted context from the knowledge base at each step. |
Iterative retrieval is a process where the knowledge base is repeatedly searched based on the initial query and the text generated so far, providing a more comprehensive knowledge base for LLMs. This approach has been shown to enhance the robustness of subsequent answer generation by offering additional contextual references through multiple retrieval iterations. This approach has been shown to enhance the robustness of subsequent answer generation by offering additional contextual references through multiple retrieval iterations.
However, it may be affected by semantic discontinuity and the accumulation of irrelevant information. ITERRETGEN uses a combined approach that integrates “retrieval-enhanced generation” and “generation-enhanced retrieval” for tasks requiring accurate information reproduction. The model harnesses the content required to address the input task as a contextual basis for retrieving pertinent knowledge, which in turn facilitates the generation of improved responses in subsequent iterations.
Recursive Retrieval
 |
|---|
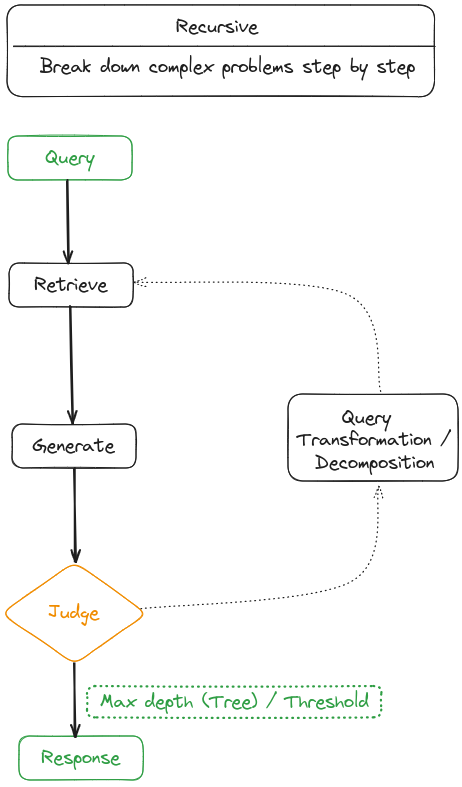
| Recursive retrieval involves gradually refining the user query and breaking down the problem into sub-problems, then continuously solving complex problems through retrieval and generation. |
Recursive retrieval is often used in information retrieval and NLP to improve the depth and relevance of the search results. The process involves iteratively refining search queries based on the results obtained from previous searches. Recursive Retrieval aims to enhance the search experience by gradually converging on the most pertinent through a feedback loop.
To address specific data scenarios, recursive retrieval and multi-hop retrieval techniques are utilized together. Recursive retrieval involves a structured index to process and retrieve data in a hierarchical manner, which may include summarizing sections of a document or lengthy PDF before performing a retrieval based on this summary. Subsequently, a secondary retrieval within the document refines the search, embodying the recursive nature of the process. In contrast, multi-hop retrieval is designed to delve deeper into graph-structured data sources, extracting interconnected information.
Adaptive Retrieval
 |
|---|
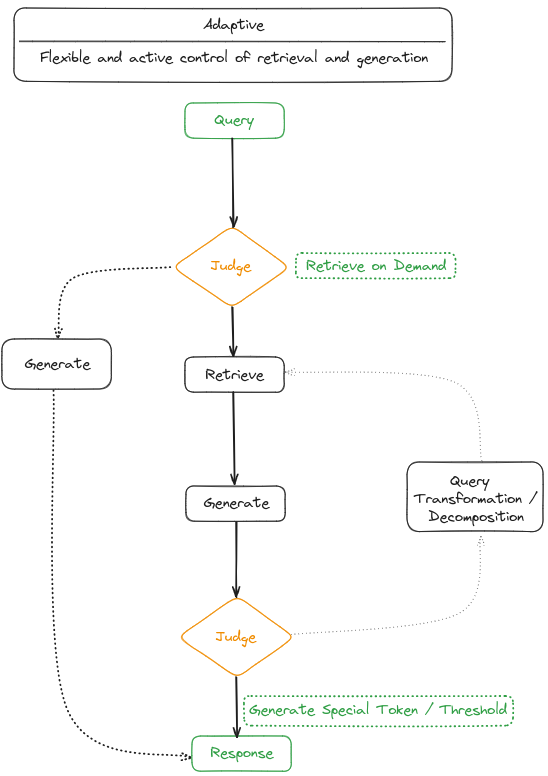
| Adaptive retrieval focuses on enabling the RAG system to autonomously determine whether external knowledge retrieval is necessary and when to stop retrieval and generation, often utilizing LLM-generated special tokens for control. |
Adaptive retrieval methods refine the RAG framework by enabling LLMs to actively determine the optimal moments and content for retrieval, thus enhancing the efficiency and relevance of the information sourced.
These methods are part of a broader trend wherein LLMs employ active judgment in their operations, as seen in model agents like AutoGPT, Toolformer, and GraphToolformer.
Wrapping Up
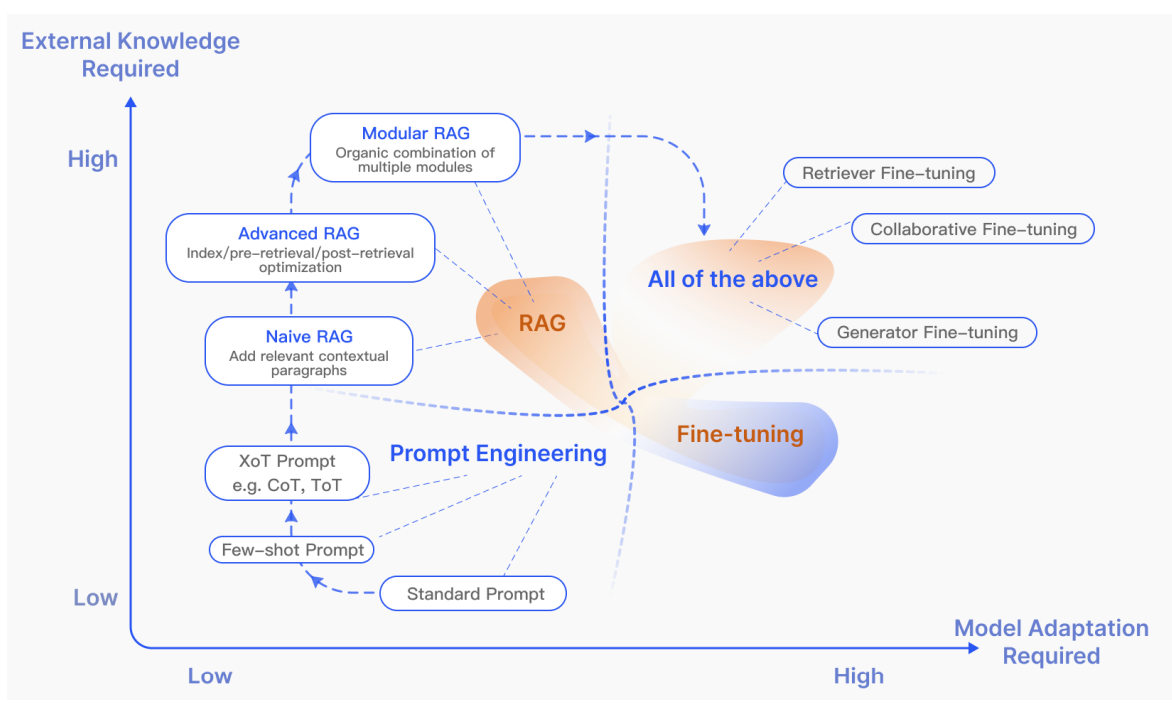 |
|---|
| As the volume of external knowledge increases, advanced techniques combined with RAG become more and more vital. |
That’s the end of the RAG series. In the context of retrieving information from vast external knowledge sources, the integration of advanced techniques with RAG is becoming increasingly essential, making it possible to achieve state of the art results in answering question in interested domains.